模型配置 - 自由选择 AI 大脑
在控制台配置自定义 AI 模型,实现模型自由切换,打造专属的 AI 角色。
核心亮点
- 🤖 多模型支持:支持 OpenAI、DeepSeek、通义千问等主流模型
- 🔌 兼容接口:支持所有 OpenAI 兼容接口
- 🎯 灵活配置:自定义 API Key、Base URL 和模型参数
- 💰 成本控制:根据需求选择不同价格的模型
- 🔄 快速切换:随时更换模型,无需重新配置设备
功能说明
模型配置功能允许你在控制台添加和管理多个 AI 模型,每个AI角色可以独立选择使用的模型。支持官方模型和自建模型服务。
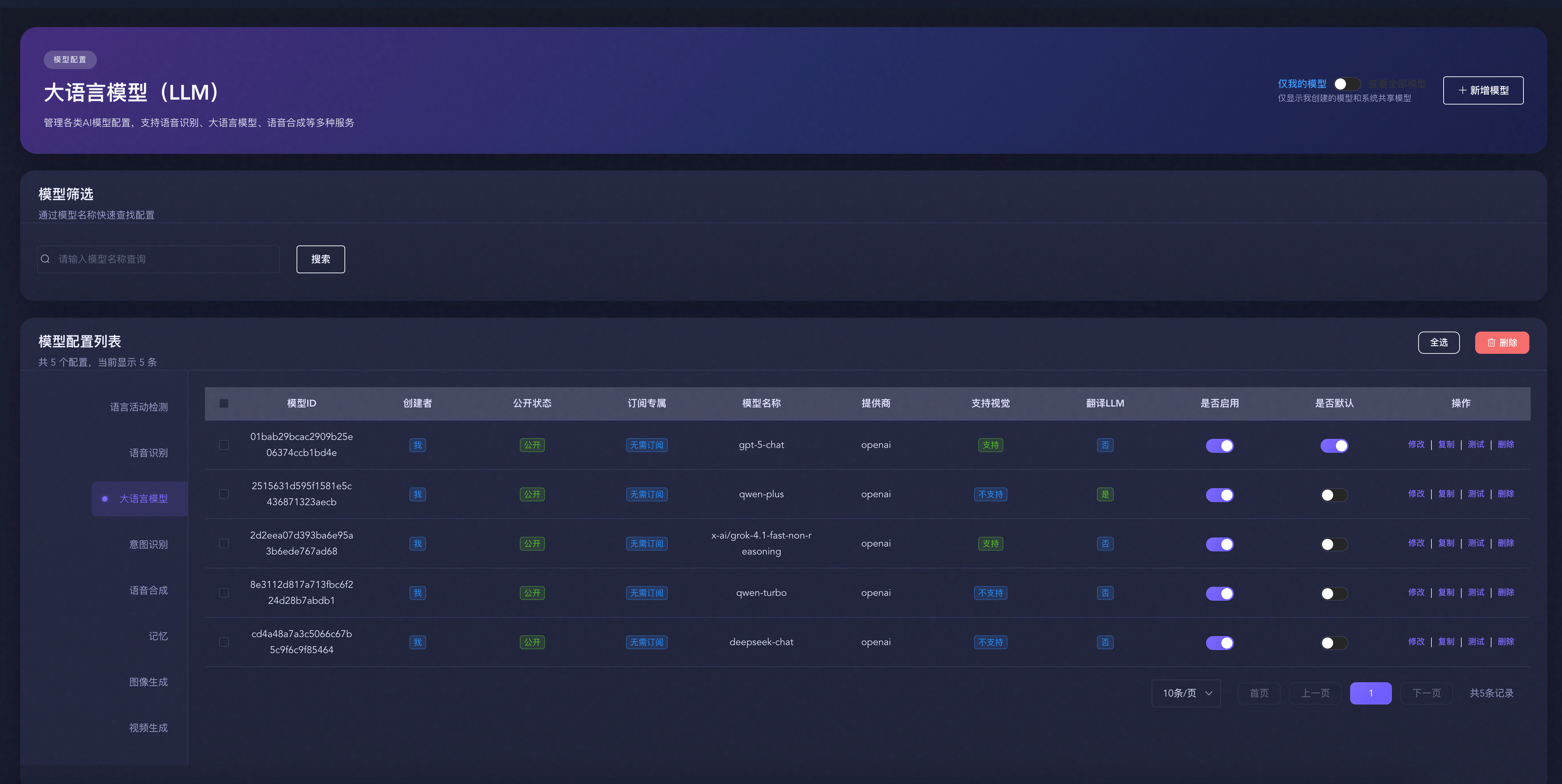
配置步骤
添加新模型
登录控制台:
- 访问 Cyber Spirit 管理后台
- 使用账号密码登录
进入模型管理:
- 点击左侧菜单"AI 能力配置" → "模型配置"
- 进入模型列表页面
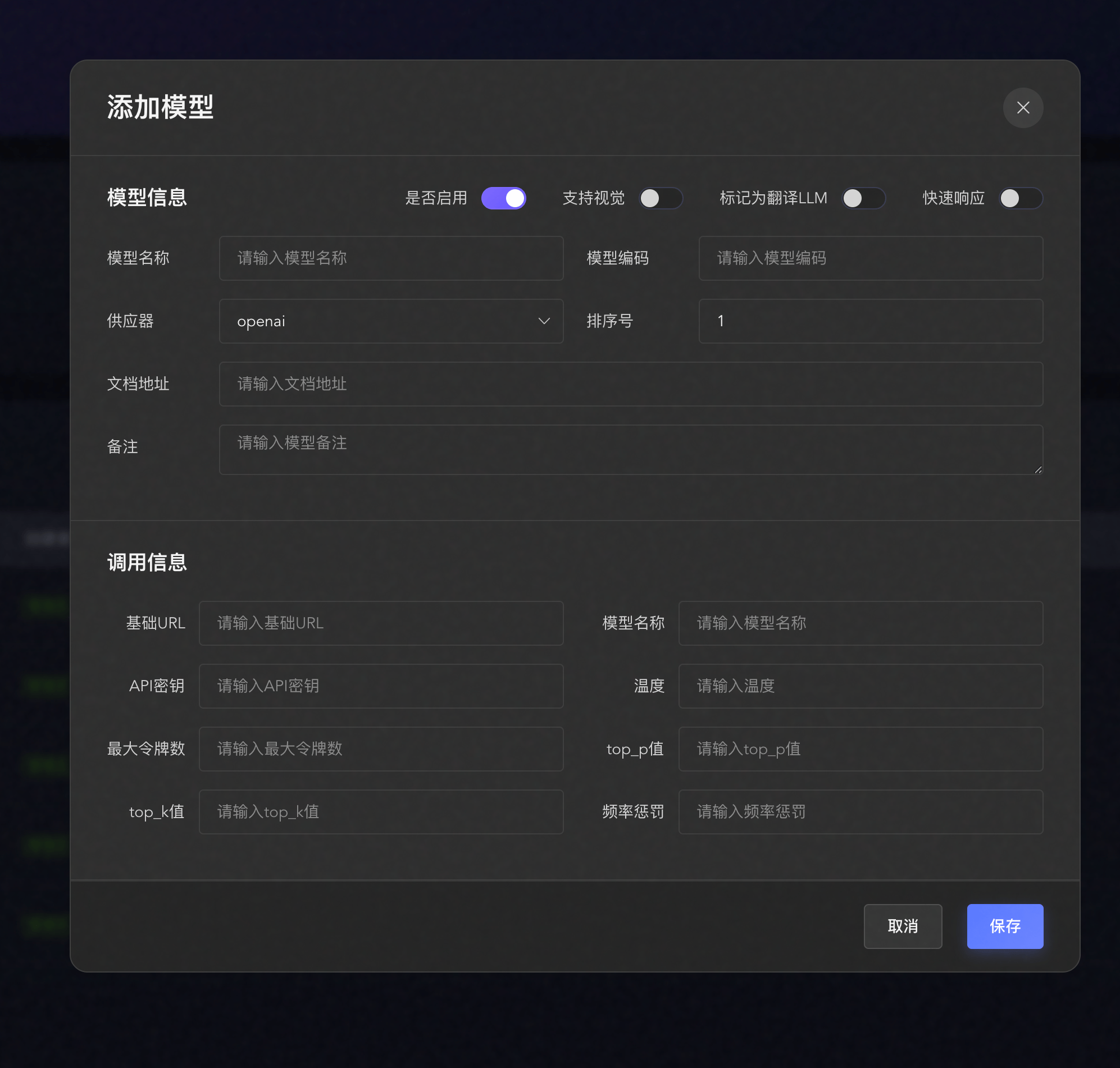
创建新模型:
- 点击右上角"新增模型"按钮
- 进入模型配置页面
填写基础信息:
- 模型名称:为模型起一个易识别的名称(如"GPT-4"、"Claude-3.5")
- 模型类型:选择模型类型(LLM、ASR、TTS)
- 服务商:选择服务提供商
配置 API 信息:
- API Key:填入从服务商获取的 API 密钥
- Base URL:填入 API 接口地址
- 模型编码:填入具体的模型名称(如 gpt-4、claude-3-5-sonnet-20241022)
高级设置(可选):
- 温度值:控制回复的随机性(0-2,默认 0.7)
- 最大 Token:单次对话的最大 Token 数
- 超时时间:API 请求超时时间(秒)
保存配置:
- 点击"保存"按钮
- 系统自动验证配置
- 配置成功后模型出现在列表中
- 可以点击测试,测试与模型的连接是否畅通
配置项详解
API Key(API 密钥)
获取方式:
- OpenAI:国内可以访问 https://zenmux.ai/invite/ROFDZC 创建
安全提示:
- ⚠️ API Key 是敏感信息,请妥善保管
- ⚠️ 不要在公开场合分享 API Key
- ⚠️ 定期更换 API Key 以提高安全性
- ⚠️ 如果 API Key 泄露,立即在服务商后台撤销
Base URL(接口地址)
官方接口地址:
- OpenAI:
https://zenmux.ai/v1
自建服务:
- 如果使用自建的模型服务(如 Ollama)
- 填入你的服务器地址(如
http://ip:端口) - 确保服务器可以被控制台访问
代理服务:
- 如果使用第三方代理服务
- 填入代理服务提供的 Base URL
- 注意代理服务的稳定性和安全性
温度值(Temperature)
控制模型回复的随机性和创造性:
- 0.0 - 0.3:非常确定性,适合事实性问答
- 0.4 - 0.7:平衡性,适合日常对话(推荐)
- 0.8 - 1.0:较高创造性,适合创意写作
- 1.1 - 2.0:极高随机性,适合头脑风暴
应用模型到AI角色
配置完成后,需要将模型应用到AI角色:
方式一:在控制台应用
进入AI角色管理:
- 点击左侧菜单"AI角色管理"
- 选择要配置的AI角色
选择模型:
- 在AI角色编辑页面找到"模型配置"
- 从下拉列表中选择刚配置的模型
- 可以分别配置 LLM、ASR、TTS 模型
保存并同步:
- 点击"保存"按钮
- 配置会自动同步到设备
- 下次对话时生效
方式二:在 App 中应用
打开 App:
- 进入"角色"页面
- 选择要配置的角色
编辑角色:
- 点击"编辑"按钮
- 找到"模型设置"选项
选择模型:
- 从模型列表中选择
- 可以预览模型信息
- 保存后立即生效
模型管理
查看模型列表
在控制台的模型管理页面可以查看所有已配置的模型:
- 模型名称:自定义的模型名称
- 模型类型:LLM、ASR 或 TTS
- 服务商:模型提供商
- 状态:启用/禁用
- 使用情况:被多少个AI角色使用
- 创建时间:模型添加时间
编辑模型
- 点击模型卡片的"编辑"按钮
- 修改配置信息
- 保存更改
删除模型
- 点击模型卡片的"删除"按钮
- 确认删除操作
注意
删除模型前,请确保没有 AI 角色正在使用该模型。如果有 AI 角色使用,需要先更换模型再删除。
启用/禁用模型
- 点击模型卡片的启用/禁用开关
- 禁用的模型不会出现在 AI 角色的模型选择列表中
- 启用的模型可以在创建角色时选择
测试模型
配置完成后,建议先测试模型是否正常工作:
在控制台测试:
- 点击模型卡片的"测试"按钮
- 输入测试文本
- 查看模型响应
在 App 中测试:
- 选择使用该模型的角色
- 进行实际对话测试
- 检查响应质量和速度
支持的服务商
LLM(大语言模型)
官方服务商:
- OpenAI:GPT-4、GPT-3.5 系列
- Anthropic:Claude 3.5、Claude 3 系列
- 阿里云百炼:通义千问系列
- Google:Gemini 系列
- 字节跳动:豆包系列
开源/自建服务:
- Ollama:本地运行开源模型
- LocalAI:本地 AI 服务
- Xinference:分布式推理框架
- FastGPT:知识库增强对话
- Dify:LLM 应用开发平台
平台服务:
- Coze:字节跳动 AI 平台
- HomeAssistant:智能家居集成
ASR(语音识别)
云服务:
- FunASR:阿里达摩院语音识别
- 豆包 ASR:字节跳动语音识别
- 阿里云 ASR:阿里云语音识别
- 腾讯云 ASR:腾讯云语音识别
- 百度 ASR:百度语音识别
- OpenAI Whisper:OpenAI 语音识别
- 通义千问 ASR:阿里云通义千问语音识别
本地服务:
- SherpaONNX:本地语音识别
TTS(语音合成)
云服务:
- EdgeTTS:微软 Edge 语音合成(免费)
- 豆包 TTS:字节跳动语音合成
- 火山引擎:字节跳动火山引擎 TTS
- 阿里云 TTS:阿里云语音合成
- 腾讯云 TTS:腾讯云语音合成
- OpenAI TTS:OpenAI 语音合成
- Minimax TTS:Minimax 语音合成
- SiliconFlow:硅基流动语音合成
- Coze TTS:Coze 中文语音合成
- TTS-On:TTS-On 语音合成
开源/自建服务:
- FishSpeech:开源语音合成
- GPT-SoVITS V2/V3:开源语音克隆
配置后模型不工作怎么办?
检查 API Key:
- 确认 API Key 正确无误
- 检查是否有多余的空格
- 确认 API Key 未过期
检查 Base URL:
- 确认 URL 格式正确
- 检查是否可以访问(网络问题)
- 确认协议(http/https)正确
检查模型标识:
- 确认模型名称与服务商一致
- 检查是否有拼写错误
- 确认该模型在你的账号下可用
查看错误日志:
- 在控制台查看详细错误信息
- 根据错误提示进行调整
如何选择合适的模型?
根据使用场景选择:
日常对话:
- 推荐:GPT-3.5-turbo、Claude 3 Sonnet、通义千问 Plus
- 特点:响应快、成本低、质量好
专业问答:
- 推荐:GPT-4、Claude 3.5 Sonnet、通义千问 Max
- 特点:理解深、推理强、准确度高
创意写作:
- 推荐:GPT-4、Claude 3 Opus
- 特点:创造力强、文笔好
成本敏感:
- 推荐:GPT-3.5-turbo、通义千问 Turbo、Ollama 本地模型
- 特点:价格低或免费
可以同时配置多个模型吗?
可以!你可以:
- 配置多个不同的 LLM 模型
- 配置多个不同的 ASR 模型
- 配置多个不同的 TTS 模型
- 为不同的AI角色选择不同的模型组合
本地模型和云端模型有什么区别?
云端模型:
- ✅ 性能强大,效果好
- ✅ 无需本地资源
- ✅ 持续更新优化
- ❌ 需要网络连接
- ❌ 按使用量付费
- ❌ 数据需上传到云端
本地模型:
- ✅ 数据隐私性好
- ✅ 无需网络连接
- ✅ 无使用成本
- ❌ 需要较强的硬件配置
- ❌ 效果可能不如云端模型
- ❌ 需要自己维护更新
模型配置会影响设备性能吗?
不会。模型配置只影响:
- 响应速度:不同模型的处理速度不同
- 对话质量:不同模型的理解和生成能力不同
- 使用成本:不同模型的价格不同
设备本身只负责音频采集和播放,AI 处理都在服务器端完成,不会占用设备资源。
如何降低使用成本?
选择性价比高的模型:
- 日常对话使用 GPT-3.5-turbo
- 简单任务使用通义千问 Turbo
- 考虑使用本地模型(Ollama)
优化提示词:
- 精简系统提示词
- 减少不必要的上下文
- 控制对话历史长度
合理设置参数:
- 降低最大 Token 数
- 适当降低温度值
- 启用缓存机制
使用免费服务:
- EdgeTTS(免费 TTS)
- Ollama 本地 LLM